관련 유튜브 : 고논채널
BioGothesis
과학 논문은 어떻게 쓰는 것인가? 과학 논문을 쓰는 방법을 한번씩 체험해보는 채널입니다 ---------------------------------------------------------------------------------------------------------------------------------------
www.youtube.com
이번 포스팅은 표를 그리는
Sigma plot라는 프로그램과
통계 프로그램은 SAS의 이용법에 대해서 다룬다.
이 두 프로그램 모두 라이센스가 필요한 프로그램이다. 독자가 대학생일 경우 학교에서 SAS의 라이센스를 제공할 가능성이 높으므로 이용에 지장이 없겠지만, 아닌 경우에는 SAS univeristy 같이 무료로 제공되는 프로그램을 써야 하는데, 기능이 제한되는 점이 있으며, 상당히 불편한 점이 있다.
그러므로 이번 강좌는 프로그램을 구할 수 없을 경우 스킵하는 것도 추천하는 바이다.
그러면 시작해보자.
1. Sigma plot의 사용법
위와 같이 엑셀을 이용해서 분석을 마치고 나면, 그래프를 그려야 한다. 그래프는 엑셀 자체에 있는 프로그램을 이용해서 그려도 되지만, Sigma plot 라는 그래프 작성 전문 프로그램을 이용하여 그려 보겠다. 그 전에 엑셀을 이용해서 표를 그리기 위해 필요한 포맷을 맞추어 보자.
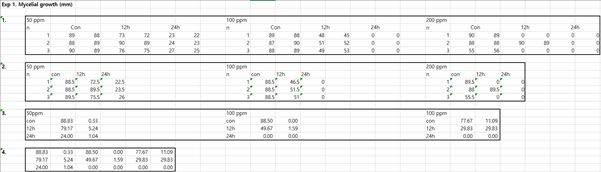
1번은 원 raw 데이터, 2번은 2개 반복 측정한 것을 평균내서 측정값으로 줄인 것,
3번은 시간별 평균값과 표준오차를 구한 것, 여기서 오른쪽은 평균 왼쪽은 표준오차다. 마지막 4번이 테이블을 만들기 위한 포맷이다. 모든 데이터는 이와 같은 방식으로 엑셀에서 정리하여 Sigmaplot으로 옮긴다.
우리는 Sigmaplot 10.0 을 이용할 것이다. 지금 현재 더 업데이트된 버전이 있으므로, 구할 수 있으면 더 최신 버전을 구해서 사용해도 무방하다.

실행시키면 위와 같은 모양으로 실행된다.
우리는 Create new blank notebook을 선택한다.

다음과 같은 화면이 나온다. 시그마플롯은 엑셀하고 비슷한 모양새를 가지며, 비슷한 기능도 상당이 많다. 하지만 어차피 두 프로그램을 쓸 거라면 엑셀에서 정리가 끝난 후 가져오는 것이 일하기에 더 편하다.

다음과 같이 X축으로 설정할 시간을 넣고 이후에 편집해 놓은 데이터를 넣는다. 우리는 막대 그래프를 그릴 예정이다. X축을 농도로 하고 싶다면 그래프를 전반적으로 바꾸어야 한다. 어떻게 해야 할지 구상해 보도록 하자 (과제).
이후 오른쪽에서 우리가 그리기 원하는 막대 그래프의 모양을 찾도록 하자. 우리는 세로로 된 막대 그래프를 그릴 것이며, 각 농도별로 그래프가 뭉쳐 있는 것을 원하며, 표준오차를 표시할 것이다.

다음과 같이 우리가 원하는 그래프를 선택하면 된다.
선택하면 다음과 같은 화면이 나온다.

이대로 할 것이므로 다음을 클릭.

x축은 시간으로 1개만 있으므로 x many y 선택

다음과 같이 x로 쓸 컬럼과 y 데이터로 쓸 컬럼, 표준오차로 쓸 컬럼을 모두 설정해 준다. 이후 마침 클릭
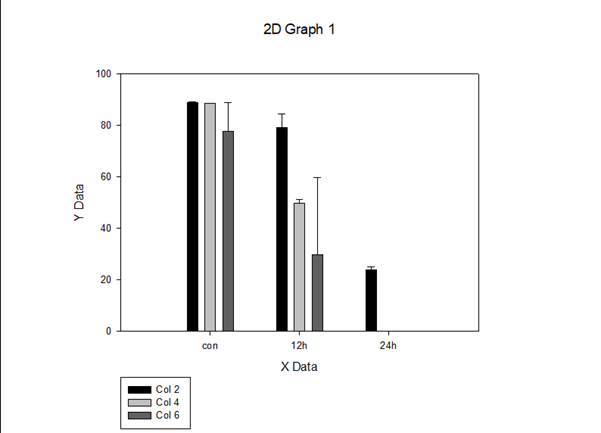
위 그림과 같은 표가 나오게 된다. 검은 막대는 50 ppm처리 회색 막대는 100 ppm 처리, 진한 회색 막대는 200 ppm처리를 나타낸다. 여기서는 Col2, 4, 6 으로 나타나 있다. 각 이름을 더블클릭하여 제대로 명명해주자. 2D Graph라는 제목을 지금 필요가 없으므로 클릭 후 del 키를 눌러 지워준다. Y 축은 Mycelial growth (mm) 라는 제목과 단위를 달아 주고 X 축은 Treatment time (h) 라는 제목과 단위를 달아 주자. 모든 글씨는 두꺼운 글씨로 바꾸고, 글씨 크기는 축은 14로 숫자는 12로 한다.

그럴듯하다.
조금만 더 나가보자. 범례 (표에 대한 설명) 는 대체로 표 안에 들어가 있으므로 표 안으로 옮긴다. 여기서 범례의 테두리가 보기 싫으므로 범례를 누르고 우클릭하면 다음과 같은 창이 나온다.
여기서 Object properties 클릭

여기서 라인을 없애자. 또한 Fill 메뉴로 들어가 채워진 색도 None으로 해 놓는 것이 나중에 편집을 할 때 편하게 되므로 반드시 채워진 색도 None로 바꾸어 놓자. 같은 요령으로 그래프와 페이지 빈 곳을 눌러서 Fill 메뉴에서 None로 바꾸어 색이 없도록 만든다. 이렇게 하는 이유는 나중에 PPT로 이 표를 가져가 편집을 할 때 배경이 있으면 작업이 매우 불편해지기 때문이다. 작업을 모두 종료하고 나면 표는 다음과 같이 회색으로 바뀌어 있게 된다. 어느 하나라도 바꾸지 않으면 흰색으로 나오니 모두 회색으로 바꾸어야 한다. (페이지는 Page setup – Page layout – page color 에서 none으로 설정)
매우 그럴 듯 하게 변했다. 하지만 여기서 라인의 픽셀이 1픽셀로 매우 얇게 나타난다. 이를 수정해보자. 이를 수정하기 위해서는 표에서 우클릭을 눌러 다음과 같은 창을 띄운다.

여기서 Graph properties 선택

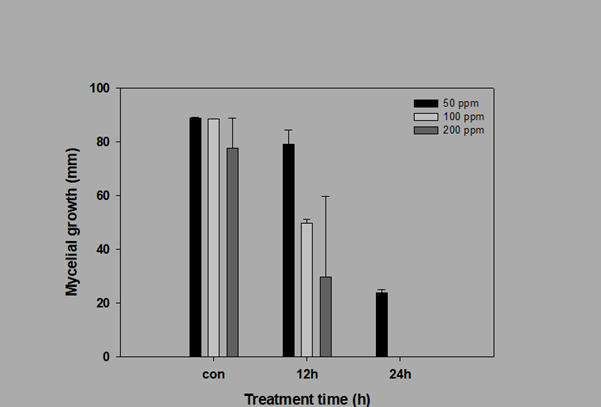
여기서는 그래프의 대부분을 조절할 수 있다. Plot 에서 widths을 눌러보자. 이후 Bar thickness에서 100 %로 적용한다. 또한 Axes를 누르면 Axis가 Treatment time (h)로 설정되 있을 것이다. 여기서 Lines에으로 들어가 Tinckness 를 0.5mm로 바꾼다. Scaling 에서는 start 값을 -0.75, end 값을 2.75로 바꾼다. 그리고 Ticks 에서도 Tickness를 0.5mm 로 바꾼다. 여기까지 했으면, Axis를 눌러 Mycelial growth (mm)로 바꾸어 Lines에으로 들어가 Tinckness 를 0.5mm로 바꾼다. 또한 Ticks 에서도 Tickness를 0.5mm 로 바꾼다. 바꿀 때마다 적용을 눌러서 바뀌는 상태를 확인하도록 한다. 모든 것을 바꾸고 나면 다음과 같은 표가 완성이 되어 있을 것이다.

이 표는 잘 못 만든 표이다. 외관적인 것은 완벽해 보이나 12시간 200ppm에서 표준오차가 너무 크게 나타났으며, Con이 con으로 오타가 났다. 범례도 두꺼운 글씨로 바꾸지 않았다. 그리고 농도별로 모아서 보여주는 것이 더 효과적일 수도 있으므로 다시 그림을 그려야만 할 것이다. 고쳐야 할 부분을 배운 것을 바탕으로 수정해 보자 (과제). 같은 방법으로 각자 더 완벽한 표를 그려 보도록 하자.
2. SAS 사용법
데이터를 가지고 표나 그래프를 그린 다음에는 통계분석을 해서 어떻게 다르고 어떻게 같은지를 나타내 주는 것이 정말 중요하다. 이를 위해서 잘 알려진 프로그램으로는 SPSS, R, SAS등이 있는데 우리 실험실에서는 SAS를 이용하여 이를 진행하도록 하겠다. 그래프를 그릴 때와 같이 SAS에 맞는 포맷으로 숫자를 바꾸어 주어야만 한다.
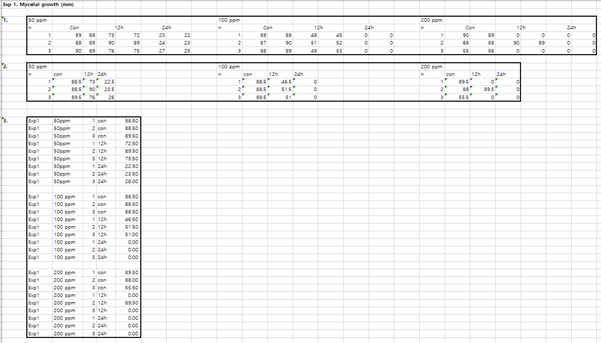
위의 3번처럼 파일을 바꾸어야 한다. SAS는 모든 파일에 위와 같이 설명을 달아 주어야 분류해서 통계 분석을 할 수 있기 때문이다. 위의 3번과 같이 파일을 바꾸고 나면 SAS를 실행시키고 분석을 해 보도록 하자. 우리는 이번에는 SAS9.4 를 이용할 것이고 이 프로그램은 매우 고가의 프로그램이지만 학교에서 라이선스를 구매하여 학생에게는 무료로 받을 수 있게 하고 있다. 포털에서 SAS를 다운받아 설치하자. SAS에서 제공하는 SAS University 라는 무료 프로그램이 있으나, 띄어쓰기와 tab을 구분하여 지원하기 때문에 매우 사용이 힘들다. 그냥 학교에서 지원하는 SAS 9.4를 이용하도록 하자.
SAS 설치가 끝났으면 실행하여 보자. 다음과 같은 화면을 만나 볼 수 있다.
우리는 파일 편집기라는 창을 통해 통계 프로그램을 작성할 것이다. 일단 어떻게 생겼는지만 보고, 바탕화면으로 나오 마우스 우클릭 후 새로 만들기에서 텍스트 파일을 만든다. SAS 파일로 저장해도 좋지만, 용량도 크고 SAS 버전이 바뀔 때마다 호환이 안 되거나 하는 문제가 생기므로 txt파일로 프로그래밍을 하고 결과를 저장해 두는 연습을 하도록 하자.
우리는 곰팡이 실험 결과를 분석할 예정이다. 예제로 exp1의 곰팡이 길이만 분석을 해 보도록 하겠다. 같은 농도를 처리했을 때, 시간별로 어떻게 차이가 나는지 분석해 보도록 하겠다. 이미 가지고 있는 Raw 데이터를 가지고 분석을 해 보도록 하겠다.
1. 제목은 Data 문으로
SAS프로그래밍의 시작은 제목을 정하는 데서 시작한다. SAS 프로그램에게 제목을 알려 주는 방법은 다음과 같다.
Data mycelial_growth;
이렇게 적으면 SAS프로그램은 이 데이터가 mycelial_growth 구나. 하고 알 수 있다. 그리고 알아두어야 할 점은 SAS는 제목에서 띄어쓰기를 인식하지 않는다. 그러므로 띄어쓰기를 하고 싶으면 반드시 _ 표를 그려서 사용해야 한다. 또한 명령이 끝나고 나면, ; 표를 그려서 이 명령이 끝났다는 것을 알려 주어야 한다. 예를 들어,
Data mycelial growth;
라고 작성을 하면 SAS는 응 이 데이터 제목은 mycelial…. 아직 입력을 다 안 했군. 이라고 인식한다는 것이다. 반드시 띄어쓰기를 인식 안 하는 것을 알고 확인해야 하고, 그리고 끝이 날 때에는 ; 표를 반드시 적어 주어야 한다. 이후 진행을 해 보면
Data mycelial_growth;
Input exp $ conc $ n $ trt $ length @@;
Cards;
Exp1 50ppm 1 con 88.50
Exp1 50ppm 2 con 88.50
Exp1 50ppm 3 con 89.50
Exp1 50ppm 1 12h 72.50
Exp1 50ppm 2 12h 89.50
Exp1 50ppm 3 12h 75.50
Exp1 50ppm 1 24h 22.50
Exp1 50ppm 2 24h 23.50
Exp1 50ppm 3 24h 26.00
Exp1 100ppm 1 con 88.50
Exp1 100ppm 2 con 88.50
Exp1 100ppm 3 con 88.50
Exp1 100ppm 1 12h 46.50
Exp1 100ppm 2 12h 51.50
Exp1 100ppm 3 12h 51.00
Exp1 100ppm 1 24h 0.00
Exp1 100ppm 2 24h 0.00
Exp1 100ppm 3 24h 0.00
Exp1 200ppm 1 con 89.50
Exp1 200ppm 2 con 88.00
Exp1 200ppm 3 con 55.50
Exp1 200ppm 1 12h 0.00
Exp1 200ppm 2 12h 89.50
Exp1 200ppm 3 12h 0.00
Exp1 200ppm 1 24h 0.00
Exp1 200ppm 2 24h 0.00
Exp1 200ppm 3 24h 0.00
;
Proc sort;
By conc;
Proc glm; by conc;
Class trt;
Model length = trt;
Means trt;
Run;
위와 같이 만들 수 있다. 지금부터 설명을 하도록 하겠다.
2. Input 문
Input 명렁어는 지금부터 넣을 데이터의 순서를 알려주는 것이다. 우리는 데이터의 순서를 EXP conc n trt length 정리했으므로 그 순서대로 넣겠다고 알려 주었다. 이 데이터 정리 순서는 작성자 마음대로 정리할 수 있지만, 분석해야 하는 숫자 데이터를 뒤로 빼야 프로그램을 짜거나 볼 때 쉽다. 또한 큰 분류일수록 앞에 두는 것이 프로그램을 짜거나 볼 때 쉽다. 각 순서에 $ 표시를 넣은 것을 볼 수 있을 것이다. 이것은 $ 표시 앞에 있는 것이 우리가 분석해야 할 값이 아니고 ‘분류’ 의 일종임을 SAS에게 알려주는 표시이다. 만약 length 와 sporulation을 동시에 분석하고 싶다면 다음과 같이 input 문을 만들어야 한다.
Input exp $ conc $ n $ trt $ length sporulation @@;
Length와 sporulation은 둘 다 우리가 분석해야 할 값이기 때문에 뒤에 $이 붙지 않는 것을 볼 수 있다.
또한 마지막에 붙는 @@ 표시는 데이터를 병렬로 나열할 수 있게 만들어주는 명령어로, 같은 세트의 데이터를 옆으로도 늘어서 쓸 수 있게 만들어 준다.
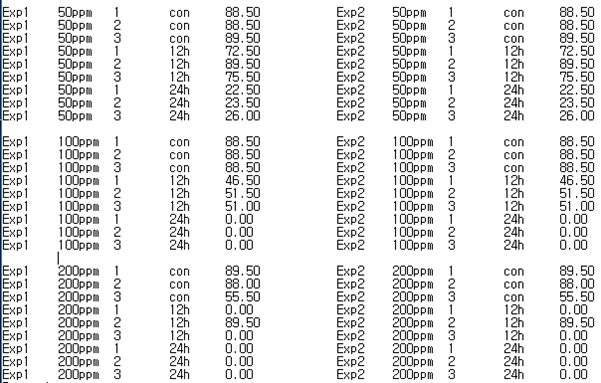
Input문 또한 끝날 때에는 반드시 ;를 붙여 끝내준다.
3. Cards 문
이후에 우리는 데이터를 집어 넣기 위한 명령을 해야 한다. 이 명령은 Cards라는 명령으로 가능하다. Cards라는 명령이 주어지면 SAS는 띄어쓰기를 인식하기 시작한다. 그렇기 때문에 단위에서 매우 조심해야 하는데, 일반적으로 작성할 때에는 숫자와 단위 사이를 한칸 띄게 되어 있다. 예를 들면 이번 예제에서 농도가 그렇다. 50_ppm (_표시를 스페이스라고 보았을 경우)이라고 작성했을 경우에 50과 ppm을 각기 다른 칼럼으로 인식하게 되므로 반드시 붙여서 써야 오류가 나지 않는다. 초보일때 매우 잘 나오는 실수이므로 프로그램이 실행되지 않거나 부분적으로만 실행되는 경우가 생기면 점검해 보도록 하자. 우리가 정리한 숫자를 모두 적어넣고 마지막은 반드시 ; 로 끝내 준다.
4. Proc 문
우리는 Proc문을 통해서 명령을 내리게 된다. 주로 내리는 명령은 sort와 anova 혹은 glm이다. Anova와 glm은 비슷하므로 이 중 더 쉽게 쓰는 glm을 이용해 보았다.
Proc sort;
이 명령은 우리 데이터를 이 기준으로 분류하라는 것이다. 우리는 농도는 고정을 해 놓고 시간별로 볼 것이기 때문에 데이터를 먼저 농도별로 구분해 놔야 한다. 그러면 다음 명령으로
By conc;
를 적어주면 된다. 만일 EXP2도 있는 상황에서, exp1 과 2를 따로 구분해서 보고 싶다면
By exp conc;
명령어에서도 띄어쓰기를 인식하므로 두 가지를 모두 적어주면 되겠다. 이후 프로그램을 실행하라는 명령인 run; 적어 주자. 그리고 마지막은 반드시 ;로 끝내야만 한다. 여기까지 진행하면 데이터는 농도별로 구분된 데이터로 정리되게 된다. 이후
Proc glm; 으로 우리가 glm분석을 할 것이라고 알려주고,
By conc;로 농도별로 볼 것임을 알려준다.
그리고는 반드시 채워야 하는 class model means를 채워 주자.
Class 는 어떤 기준으로 이 데이터를 분석할지 나누는 것이다. 우리는 처리 시간으로 나눌 것이기 때문에,
Class trt;
(사실 Class는 독립변인을 적어 주는 곳이다. 독립변인은 실험의 결과에 영향을 주는 변인을 말한다. 여기서는 시간이 그 변인이고.)
가 될 것이다. 그리고 model은 이 class에 영향을 받는 우리가 분석해야 하는 값을 연결시켜 주어야 한다. Y=aX+b 를나타내는 방법과 같다고 생각하면 된다.
Model length = trt;
로 나타내 주어야 한다.
(마찬가지로 model은 종속 변인과 독립변인의 관계를 나타내 주는 모양이어야 한다. 종속변인 = 독립변인 순으로 쓴다.)
여기서 sporulation 을 같이 보고 싶었다면 다음과 같이 쓴다.
Model length sporulation = trt;
이러면 두 분석값이 같이 나오게 된다.
분석 이후에는 평균값으로 써 주는 것이 좋기 때문에
Means명령어를 쓰고 이 값은 trt에 대한 값이므로,
Means=trt;
그리고 실행 명령어인 run; 으로 프로그램을 마치면 된다.
Means 뒤에는 통계값을 확인하는 방법으로
Means = trt/ lsd lines;
를 붙이면 lsd로 통계값을 나누어서 보여주게 된다.
데이터 입력 부분은 위와 같으며
Proc sort;
By conc;
Proc glm; by conc;
Class trt;
Model length = trt;
Means trt/lsd lines;
Run;
만 추가된다. 명령어 입력 끝에는 반드시 ;를 붙여 명령이 끝났음을 알려주어야 한다.
5. 데이터 변환
이 이외에 데이터가 퍼센트 데이터이고 정규분포가 아닌 경우 (30 이하 70이상으로 쏠린 경우)에는 Arcsin 변환을 해서 데이터 분석을 해야만 한다. 그리고 sporulation의 경우에는 log 변환을 한 뒤 데이터 분석을 하는 것이 맞다. 데이터를 변환하는 방법은 다음과 같다.
Data paratice;
Input exp $ conc $ n $ trt $ percent sporulation;
A = sqrt (percent/100);
B = arsin(A);
Tpercent=B*180/3.141592;
C= log(sporulation+1);
Tsporulation=C;
위와 같이 프로그램을 짠 뒤, 이후는 위에 설명과 같이 분석을 실시하면 된다. 단
Proc sort;
By conc;
Proc glm; by conc;
Class trt;
Model percent = trt;
Means trt/lsd lines;
Run;
과 같이 넣는 것이 아니고 변환값을 넣어야 한다.
Proc sort;
By conc;
Proc glm; by conc;
Class trt;
Model Tpercent = trt;
Means trt/lsd lines;
Run;
로그값의 경우도 마찬가지로 sporulation 을 넣는 것이 아니고 Tsporulation을 넣어야 변환된 값으로 분석이 가능하다. 명령어 입력 끝에는 반드시 ;를 붙여 명령이 끝났음을 알려주어야 한다.
6. 데이터를 합치기
모든 실험은 반복 실험을 통해서 이 실험이 맞는지를 검증해야만 한다. EXP1 과 EXP2 혹은 EXP1과 EXP3의 실험이 같은 경향을 나타내고 있다면 이 데이터를 합쳐서 표를 만들면 더 좋은 실험 결과를 독자들에게 보여 줄 수 있게 된다. 데이터를 합치기 위해서는 levene’s test를 진행한다. 두개의 실험을 골라 데이터로 사용하고, 분석 방법은 다음과 같다. 분석해야 하는 값을 length라고 가정하자.
Proc glm;
Class exp;
Model length = exp;
Means exp/hovtest=levene;
Run;
이 테스트의 결과 값으로는

위와 같은 값이 나오게 되는데. P값이 0.05보다 클 경우 두 집단 사이에 유의한 차이가 없는 것으로 가정하여 합칠 수 있다. 만약 0.05보다 작은 값이 나올 경우에는 합칠 수 없다. 하지만 경향이 같게 나온다면 따로 테이블이나 그래프를 그려서 나타내 주는 것도 아주 좋은 데이터 표현 방법이 된다.
3. 데이터 분석하기
지금까지 우리가 배운 Excel사용법 Sigma plot 사용법 그리고 SAS 사용법은 가르쳐 주는 사람이 있다면 누구라도 따라서 할 수 있는 기술의 영역이다. 하지만 지금부터 배우는 데이터 분석의 영역은 많은 논문을 읽고, 아이디어를 가지고, 가설을 설정하고, 스스로를 속이지 않으며, 논문을 작성하기 위한 모든 지식이 농축되어 있어야만 할 수 있는 영역이다. 이 눈을 가지고 있느냐 있지 않느냐에 따라 좋은 과학자가 될 수도 있고 아닐 수도 있는 것이다. 데이터를 볼 때에는 객관적인 눈을 가지고 봐야 하며, 예측과 어긋난 데이터가 있을 경우, 이것이 왜 나타났는지에 대한 생각을 해 볼 필요가 있다. 혹시 처리가 되지 않은 것은 아닌가, 샘플이 바뀐 것은 아닌가, 반복 실험에도 같은 결과가 나오는가를 끊임없이 인식하고 의심해야 좋은 데이터가 나올 수 있으며, 한가지 기준에 맞춰서 이 데이터를 정리해 낼 수 있어야만 한다. 객관적으로 잘못된 실험결과를 걸러내어 좋은 실험결과를 가지고 사리에 맞는 통계처리를 하여 연구를 진행해야 한다. 주어지는 Raw데이터를 보고 어떤 데이터가 이상하며 그 이상한 데이터가 어떤 실험의 결과인지를 유추해 보도록 하자.
SAS 프로그램을 돌리고 난 뒤, 샘플이 정규분포를 했다는 가정 하에 (샘플이30개 이상) 결과값은 P값을 중심으로 0.05보다 작을 경우에만 lsd등의 통계값이 유의한 것임을 알고 그래프나 표에 사용하도록 한다.
4. 오늘의 과제
오늘의 과제는 엑셀을 이용하여 데이터를 정리하고 시그마 플롯을 이용하여 독자에게 데이터를 한눈에 보여 줄 수 있는, 규격에 맞는 표를 그리고, SAS를 이용하여 통계값을 만들어내는 것이다. 마지막으로는 Raw데이터를 보면서 어떤 데이터를 배제하고 어떤 데이터를 선택해서 최종 표와 그래프를 작성해야 하는지 결정하고 이 결정을 바탕으로 최종 표와 그래프를 작성해보도록 하자.
논문작성법 - 1-2. 논문을 쓰는 이유/ 1-3. 1저자의 요건/1-4. 과제
논문작성법 - 2. 논문을 찾는 방법 - 구글 스칼라 이용
논문작성법 - 2. 논문을 찾는 방법 - 논문을 읽는 방법에 대해서
논문작성법 - 4. 데이터 분석 - Sigma plot 사용과 SAS 사용법
논문작성법 - 6. Introduction/ Discussion 작성논문작성법 - 6. Introduction/ Discussion 작성
'논문작성법[完]' 카테고리의 다른 글
| 논문작성법 - 6. Introduction/ Discussion 작성 (7) | 2020.08.26 |
|---|---|
| 논문작성법 - 5. Results의 작성 (0) | 2020.08.26 |
| 논문작성법 - 4. 데이터 분석 - 엑셀 사용법 (2) | 2020.08.24 |
| 논문작성법 - 3. 실험계획 세우기3 (0) | 2020.08.22 |
| 논문작성법 - 3. 실험계획 세우기2 (0) | 2020.08.21 |


